一、引言
每次下载一个新App,弹出来的第一件事就是要求用户勾选“我已阅读并同意《隐私政策》”——但扪心自问,真的读过吗?就算读了,真的读懂了吗?
这并不是用户的问题。移动互联网时代,隐私政策已经成为平台履行个人信息告知义务的核心文件。社交媒体、电子商务、移动医疗、智慧出行……各类应用在提供便捷服务的同时,也在持续不断地收集并处理大量用户个人信息——身份信息、设备型号、地理位置、消费记录,一个都不少。
问题的关键在于:许多隐私政策虽然形式上完整,但实际表述中存在大量模糊、不确定或过于概括的描述。平台在写隐私政策的时候,大量使用“可能”“必要时”“相关服务”“包括但不限于”之类的词汇。这些词单独看没问题,但当它们密集出现在“收集”“使用”“共享”“转让”等关键数据处理条款中时,用户就很难准确判断:平台到底收集了什么?在什么条件下会与第三方共享?数据会保存多久?删除机制是什么?
从法律层面看,《中华人民共和国个人信息保护法》明确规定,个人信息处理者应当以清晰、明确的方式向用户说明信息处理的目的、方式及范围。但从用户的实际感受来看,很多隐私政策距离“清晰、明确”还有不小的距离。
更令人担忧的是,数据泄露事件仍在频繁发生。CyberNews研究人员发现的160亿登录凭证遭到曝光;Qantas航空第三方平台被攻破导致600万名旅客个人资料泄露。这些事件背后,隐私政策表述不清、用户难以真正知情同意,是一个不可忽视的诱因。
本研究的目标:构建一套可量化、可解释的隐私政策模糊性评价方法,并实现自动化评估工具,让“隐私政策好不好读”这件事,不再是凭感觉,而是有数据、有标准。
二、问题界定:什么是隐私政策的“表述模糊性”?
2.1 核心概念
在开始搭建评价体系之前,先要把“什么是模糊”这件事说清楚。本文围绕隐私政策最基本的功能——平台能不能把个人信息处理活动跟用户说清楚——定义了以下核心概念:
告知明确性:衡量隐私政策对个人信息处理行为的描述是否具体、边界是否清晰、适用条件是否明确。简单说,就是文本说得清不清楚。
可读性:衡量用户能不能读懂这篇文章——句子长不长、术语多不多、结构乱不乱。简单说,就是用户读不读得懂。
可达性:用户能不能方便地找到隐私政策入口?是在首页显眼位置,还是藏在三级菜单里?
互动性:阅读隐私政策时有没有辅助功能?比如目录导航、关键词搜索、折叠展开?
权利完整性:政策有没有提到访问权、更正权、删除权、撤回同意权等用户权利?
信息安全性:政策有没有说明数据加密、存储保护、泄露应对等安全措施?
其中,告知明确性和可读性共同构成了评价体系的核心维度,两者各占50%的权重。可达性和互动性作为辅助维度单独统计,不参与核心总分。权利完整性和信息安全性作为合规对比维度,同样不纳入核心总分。
2.2 模糊表达四大类型
为了保障评价过程的一致性,本文将隐私政策中的模糊表述划分为四种常见类型:
| 类型 | 示例 | 问题所在 |
|---|---|---|
| 情态类 | 可能、可以、或许、也许 | 体现不确定性,大量出现时降低平台承诺的确定性 |
| 条件类 | 根据需要、在必要时、视情况而定 | 缺少清晰的触发条件,用户无法判断何时会发生数据处理 |
| 泛化类 | 一般、通常、部分、合理、适当 | 扩大政策表达范围,让处理边界变得模糊不清 |
| 列举类 | 包括但不限于、例如、等、诸如 | 常用在列举数据类型或使用场景,但没有给出完整范围 |
这些词本身在自然语言中很常见,但当它们大量出现在隐私政策的关键条款中,就会让用户对平台的实际行为产生模糊认知。
2.3 分析单元
在具体分析时,本文将隐私政策文本拆解为三个层次的分析单元:
词级:统计各类模糊词出现的频率,这是模糊性识别中最基本的颗粒度。
句级:考察模糊表达在文本结构中的分布——模糊词是出现在背景说明里,还是集中在核心条款中?后者风险明显更高。
行为语义级:引入“行动+信息对”的概念,即在同一句或同一语义片段中,同时出现数据处理动作(收集、使用、共享、披露、转让、存储、删除等)和信息对象的描述。如果这些关键行为句中出现了较多模糊词,风险会显著高于普通说明句。
三、评价指标体系设计(三层架构)
3.1 核心维度:告知明确性
告知明确性的计算采用三层结构,从词级、语境级、句级三个层面综合评估:
第一层:分类统计
将模糊词分为四类,分别赋予不同权重:
| 模糊词类别 | 权重 | 示例 |
|---|---|---|
| 模态类(modality) | 0.4 | 可以、可能、或许 |
| 条件类(condition) | 0.25 | 根据需要、在必要时 |
| 泛化类(generalization) | 0.2 | 一般、通常、部分 |
| 列举类(numeric) | 0.15 | 包括但不限于、例如 |
之所以采用分类加权,是因为不同类型的模糊词对文本确定性的影响不同——“可能”对行为边界的影响远大于“例如”,因此权重更高。
第二层:语境惩罚
仅统计模糊词频次会遗漏语境风险。如果模糊词出现在含有关键动作词(收集、使用、共享、披露、转让、存储、处理、删除、访问、更正、撤回等)的句子中,其风险应高于普通说明句。
第三层:句子级惩罚
对长度超过20个字符且包含模糊表达的句子施加额外惩罚。因为长句加上模糊表达之后,可理解性会大幅下降,特别是在隐私政策这种法律化特征很突出的文本中。
汇总与归一化
三层结果汇总后得到总模糊强度
3.2 核心维度:可读性
可读性采用轻量化线性模型,基于平均句长和复杂词比例进行评估
3.3 总分融合与等级映射
在获得告知明确性和可读性两个核心维度得分后,按照等权方式计算表述模糊性总分。这样的设计是为了维持两项核心指标在“有效知情同意”中具有同等重要性,避免单一维度主导结果。
根据总分将样本映射为五个等级:
| 分数范围 | 等级 |
|---|---|
| ≥ 85 | 优秀 |
| [75, 85) | 良好 |
| [60, 75) | 一般 |
| [45, 60) | 较差 |
| < 45 | 极差 |
需要强调的是:高分并非意味着完全合法,低分也不等于政策违法。评价结果体现的是隐私政策在表达质量方面的相对高低,而非对平台全面合规状况的法律评判。
3.4 辅助与合规维度
- 可达性:通过三个维度打分——链接是否存在(40%)、位置是否显著(30%)、移动端是否可快速加载(30%)。
- 互动性:检查是否有目录/导航(30分)、搜索/查询功能(20分)、折叠展开(30分)、个性化解释(20分)。
- 权利完整性:检查访问、更正、删除、撤回、可携带、解释、投诉七类关键词,每缺失一类扣12分。
- 信息安全性:检查加密、存储保护、泄露响应、安全评估、安全防护五类关键词,每缺失一类扣16分
四、自动化评价方法实现(Python)
4.1 系统架构
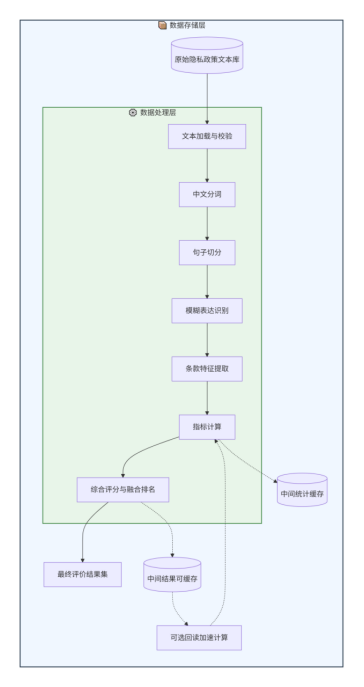
整个评价方法采用分层设计,划分为数据存储层和数据处理层。
数据存储层负责管理输入样本(.txt格式)、中间统计缓存和最终结果集(.csv)。每份样本以“编号_类别”方式命名(如“1_Exercise_health”),便于追溯和统计分析。
数据处理层是核心,按照以下流程执行:
文本加载与校验 → 中文分词与句子切分 → 模糊表达识别 → 条款特征提取 → 指标计算 → 综合评分与融合排名 → 结果导出
整个流程中,分词和句子切分是最基础的操作,后续所有识别与计算都依赖于此。
4.2 关键模块实现
预处理模块:读取文本,检查是否为空或存在编码异常;调用jieba进行中文分词;过滤掉无效样本。
告知明确性模块:预置四类模糊种子词并分别统计;检测每个句子是否包含动作词和模糊词来计算语境惩罚;统计长度超20字符且含模糊词的句子计算句子级惩罚;最后汇总并归一化。
可读性模块:依据句号、问号、感叹号、分号及换行符切分句子;计算平均句长和复杂词比例;按线性公式计算得分并进行边界截断。
辅助与合规模块:基于正则匹配关键词进行检索和计分。
结果汇总模块:按总分降序生成排名(同分同名),导出CSV文件(UTF-8-SIG编码,便于Excel直接打开)。
五、实验验证与结果分析
5.1 样本与实验环境
实验收集了国内主流互联网应用的隐私政策文本,经过清理后得到516份有效样本,涵盖购物、新闻、游戏、金融、健康等多个类别。实验环境为Windows 10 64位系统,Python 3.x,依赖pandas、jieba、re、tqdm等库。
5.2 核心指标统计
| 指标 | 均值 | 中位数 | 标准差 | 最小值 | 最大值 |
|---|---|---|---|---|---|
| 告知明确性得分 | 94.95 | 95.00 | 0.69 | 80.2 | 95.0 |
| 可读性得分 | 72.08 | 73.90 | 9.20 | 30.0 | 90.2 |
| 表述模糊性总分 | 83.52 | 84.45 | 4.59 | 62.5 | 92.6 |
关键发现:
- 告知明确性高度集中:均值为94.95,标准差仅为0.69,说明大多数隐私政策在关键条款的表述上已经有较高的明晰程度,文本中直接出现明显模糊表述的情况较少。这反映出当下主流互联网应用在隐私政策架构方面已经形成比较规范的模式。
- 可读性差异显著:标准差高达9.20,说明不同平台在隐私政策表述复杂度方面存在明显差别。有的平台用简约结构和短句式,用户容易理解;有的则句子过长、术语过多,阅读难度被大幅提高。
- 总分整体良好:均值为83.52,说明大多数样本的综合评分处在良好范围,但仍有改进空间,特别是在降低阅读复杂度和提高用户理解效率方面。
5.3 等级分布
| 等级 | 样本数 | 占比 |
|---|---|---|
| 优秀(≥85) | 200 | 38.76% |
| 良好([75, 85)) | 290 | 56.20% |
| 一般([60, 75)) | 26 | 5.04% |
| 较差([45, 60)) | 0 | 0% |
| 极差(<45) | 0 | 0% |
约94.96%的样本处于“优秀”或“良好”等级。这表明大多数平台在隐私政策文本结构方面已经具备一定规范性,但仍有少量样本在表达清晰度或可读性方面存在不足。
5.4 辅助与合规维度
| 维度 | 均值 | 中位数 | 标准差 |
|---|---|---|---|
| 可达性 | 78.10 | 100.00 | 25.43 |
| 互动性 | 75.04 | 70.00 | 24.38 |
| 权利完整性 | 87.05 | 88.00 | 16.30 |
| 信息安全性 | 79.94 | 84.00 | 14.44 |
关键发现:
- 可达性两极分化:标准差高达25.43,说明不同平台对隐私政策入口的设计差异巨大。有的放在首页或设置页显眼位置,有的则需要经过多级页面才能找到。
- 互动性参差不齐:部分平台提供目录导航、关键词检索或折叠阅读等功能,方便用户定位重点内容;但也有平台依然使用传统长篇文章形式,没有任何阅读辅助手段。
- 安全披露相对薄弱:信息安全性得分(79.94)明显低于权利完整性(87.05),说明部分平台在数据加密、存储保护、泄露应对等安全措施的阐述上比较简短,不够详细。
5.5 人工核验
为进一步验证方法输出的可靠性,从516份样本中随机抽取20份进行人工核验。
| 核验等级 | 含义 | 数量 | 占比 |
|---|---|---|---|
| 1 | 基本一致/合理 | 9 | 45% |
| 2 | 可解释但略偏高 | 10 | 50% |
| 3 | 明显异常(需纠错) | 1 | 5% |
结论:总体呈现出模型打分与文本特征大致相符,方法输出的结果有不错的稳定性以及可解释性,能够达到隐私政策模糊性识别任务的基本要求
六、浏览器插件:让评价触手可及
为进一步验证评价方法的实用性与可推广性,本研究开发了一款面向普通用户的Chrome浏览器插件。
6.1 功能与工作流程
插件采用Manifest V3标准开发,工作流程如下:
- 文本提取:通过DOM分析自动识别当前页面的隐私政策正文,或查找相关超链接获取完整文本
- 本地评分:在浏览器本地完全复现本文定义的告知明确性与可读性方法
- 多维度输出:同时输出可达性、互动性、权利完整性、信息安全性等辅助与合规指标
- 大模型增强(可选):调用兼容OpenAI接口的大模型对评分结果和原文片段生成改进建议与模糊条款定位
隐私保护:除可选的大模型分析时按需发送约4000字符外,隐私政策文本始终在本地处理,不上传至第三方服务器。
6.2 实际案例:某国内汽车品牌官网
插件在某国内汽车品牌官网隐私政策页面上的运行结果显示:
- 告知明确性:95分——关键条款中较少出现“可能”“根据需要”等模糊词
- 可读性:45分——文本句子偏长、专业术语密集,普通用户阅读负担较重
- 权利完整性:100分——用户权利阐述较为完整
- 信息安全性:部分缺失——“泄露响应”“安全评估”等关键词缺失,提示平台需补充数据泄露应对机制
这一结果与人工阅读感受基本一致,验证了插件评分结果的合理性【7†L18-L19】。插件还支持接入大模型(如qwen-max)进行辅助分析,能够定位具体模糊表述类型并给出可操作的优化建议。
6.3 与批量方法的一致性检验
随机选取10份隐私政策文本,分别使用插件和批量Python方法计算表述模糊性总分:
| 样本 | 批量方法 | 插件 | 偏差 |
|---|---|---|---|
| 1_news_reading | 92.6 | 92.6 | 0 |
| 2_online_shopping | 88.4 | 88.4 | 0 |
| 3_online_games | 78.3 | 78.3 | 0 |
| …(共10份) | … | … | 全部为0 |
统计结果表明,插件与批量方法在相同文本上的评分完全一致,绝对偏差均为0。这是因为插件直接移植了批量方法中的核心代码,确保了评价方法的统一性和可复现性。
七、总结与展望
7.1 研究贡献
本文围绕隐私政策文本表述模糊性问题,完成了以下工作:
- 构建了评价指标体系:以告知明确性和可读性为核心维度,以可达性和互动性为辅助维度,以权利完整性和信息安全性为合规对比维度,形成了一套兼顾文本表达质量和用户理解体验的分层评价框架。
- 实现了自动化评价方法:基于Python开发了隐私政策模糊性自动化评价程序,实现了文本读取、分词处理、句子切分、指标计算、综合评分、等级映射及结果导出的完整流程,可对大规模样本进行批量处理。
- 完成了实证验证:对516份真实隐私政策样本进行了批量实验,并通过人工核验证明了方法的稳定性和可解释性。
- 开发了浏览器插件:将评价方法从离线部署扩展到用户可随时调用的浏览器插件,增强了方法的实用性和可推广性。
7.2 当前局限
- 规则依赖:当前方法主要依靠规则和词典执行识别任务,对隐性语义和复杂语境的领悟能力较弱,面对含义晦涩或结构繁杂的句子时可能产生评分误差【8†L15-L16】。
- 样本覆盖:样本数量虽有516个,但从行业覆盖面和时间跨度来看仍需扩充【8†L16-L17】。
- 用户交互数据缺失:可达性和互动性的评定主要依据文本中的提示,未融合真实的用户交互数据或页面架构信息。
7.3 未来方向
- 语义增强:在既有规则框架基础上,引入语义分析或机器学习方法,通过规则与语义融合来加强模型对复杂表达的识别能力。
- 样本扩展:加大样本数量,拓展行业覆盖面,针对不同种类应用和不同版本的隐私协议开展纵向对比分析。
- 平台化:将离线分析工具拓展为可视化评价平台,既能自动评分,又能定位高风险条款并给出针对性改良意见,在监管评定、企业自主合规检查以及公众隐私认知等方面发挥更大实用价值。
结语
隐私政策的“透明度”不应只是一纸空文,而是用户信任的基石。一套客观、可量化的评价标准,不仅可以帮助监管机构高效开展抽检工作,也可以指导互联网平台优化隐私政策文本,更能让普通用户在选择使用某个应用时,多一份知情、少一份盲目。
正如本文实验所揭示的:大多数平台已经把“该写的都写了”,但远未做到“让用户看得懂” 。从“告知明确”到“用户理解”,中间还有很长的路要走。希望这套方法能为此贡献一份微薄的力量。
附录
源代码——模糊性评价计算方法
# -*- coding: utf-8 -*-
import os
import re
import jieba
from collections import Counter
import pandas as pd
from tqdm import tqdm
ROOT_FOLDER = r"F:\main files\Graduation project\main_program_result\sample_500" # ← 改成你的文件夹
OUTPUT_FINAL = r"F:\main files\Graduation project\main_program_result\0422_sample_500_result\per_policy_evaluation_final_v17.csv"
# ====================== 模糊种子词分类(Bhatia理论) ======================
VAGUE_CATEGORIES = {
"modality": {"可以", "可能", "可能会", "或许", "或", "或者", "也许"},
"condition": {"根据需要", "在必要时", "视情况", "视情况而定", "根据实际情况", "酌情"},
"generalization": {"一般", "通常", "大部分", "多数", "部分", "某些", "一些", "合理", "适当", "尽可能", "尽量"},
"numeric": {"包括但不限于", "诸如", "例如", "等"}
}
ACTION_WORDS = {"收集", "使用", "共享", "披露", "转让", "存储", "处理", "保留", "删除", "访问", "更正", "撤回"}
def calculate_accessibility(text: str) -> float:
score = 0.0
if re.search(r'https?://|本政策链接|隐私政策地址|查看完整政策', text): score += 40
if re.search(r'页脚|设置|首页|footer|setting|policy link', text, re.I): score += 30
if re.search(r'移动端|手机|响应式|加载|3秒|快速访问', text): score += 30
return round(max(0, min(100, score)), 1)
def calculate_interactivity(text: str) -> float:
score = 0.0
if re.search(r'目录|1\.|第一章|章节|展开|折叠|导航', text) or len(re.findall(r'^\d+\.', text, re.M)) >= 3: score += 30
if re.search(r'搜索|查询|查找|keyword|search', text): score += 20
if re.search(r'展开|折叠|详情|可视化|图表|仪表盘', text): score += 30
if re.search(r'解释|个性化|聊天|问答|AI|对话', text): score += 20
return round(max(0, min(100, score)), 1)
def calculate_rights_score(text: str) -> dict:
RIGHTS_KEYWORDS = {"access": ["访问", "查阅", "获取", "知情"], "correction": ["更正", "修正", "修改"], "deletion": ["删除", "删除权"], "withdraw": ["撤回", "撤销同意"], "portability": ["转移", "数据可携带"], "explanation": ["解释", "说明", "告知"], "complaint": ["投诉", "异议"]}
missing = [key for key, kws in RIGHTS_KEYWORDS.items() if not any(kw in text for kw in kws)]
score = max(0, 100 - 12 * len(missing))
return {"score": score, "missing": "; ".join(missing) if missing else "无明显缺失"}
def calculate_security_score(text: str) -> dict:
SECURITY_KEYWORDS = {"encryption": ["加密"], "storage": ["存储", "保存"], "breach": ["泄露", "数据泄露"], "assessment": ["安全评估", "风险评估"], "protection": ["保护", "安全保护措施"]}
missing = [key for key, kws in SECURITY_KEYWORDS.items() if not any(kw in text for kw in kws)]
score = max(0, 100 - 16 * len(missing))
return {"score": score, "missing": "; ".join(missing) if missing else "无明显缺失"}
def calculate_readability_score(text: str, words: list) -> float:
sentences = [s for s in re.split(r'[。!?;\n\n]', text) if len(s.strip()) > 5]
if not sentences: return 60.0
avg_len = sum(len(s) for s in sentences) / len(sentences)
complex_ratio = sum(1 for w in words if len(w) >= 3) / len(words) * 100
score = 100 - (avg_len * 0.4 + complex_ratio * 0.3)
return round(max(30, min(95, score)), 1)
# ====================== v17核心:告知明确性三层评分 ======================
def calculate_vague_clarity_score(text: str, words: list) -> float:
"""告知明确性(权重50%):分类 + 上下文行动-信息对 + 句子级"""
# 1. 分类统计
category_counts = {cat: 0 for cat in VAGUE_CATEGORIES}
for cat, seeds in VAGUE_CATEGORIES.items():
for seed in seeds:
category_counts[cat] += sum(1 for w in words if w == seed)
weights = {"modality": 0.4, "condition": 0.25, "generalization": 0.2, "numeric": 0.15}
weighted_vague = sum(category_counts[cat] * weights[cat] for cat in VAGUE_CATEGORIES)
# 2. 行动-信息对上下文
sentences = re.split(r'[。!?;]', text)
a_i_pairs = 0
vague_in_pair = 0
for sent in sentences:
if any(act in sent for act in ACTION_WORDS):
a_i_pairs += 1
if any(any(seed in sent for seed in seeds) for seeds in VAGUE_CATEGORIES.values()):
vague_in_pair += 1
context_penalty = (vague_in_pair / max(a_i_pairs, 1)) * 30 if a_i_pairs > 0 else 0
# 3. 句子级模糊
fuzzy_sentences = sum(1 for sent in sentences if len(sent.strip()) > 20 and
any(any(seed in sent for seed in seeds) for seeds in VAGUE_CATEGORIES.values()))
sentence_penalty = (fuzzy_sentences / max(len(sentences), 1)) * 20
total_vague = weighted_vague + context_penalty + sentence_penalty
total_words = len(words)
vague_score = total_vague / max(total_words, 1) * 100
vague_norm = 100 - vague_score * 1.2
return round(max(30, min(95, vague_norm)), 1)
def process_per_policy(filepath: str) -> dict:
with open(filepath, 'r', encoding='utf-8') as f:
text = f.read().strip()
if not text: return None
app_name = os.path.basename(filepath)[:-4]
words = jieba.lcut(text)
if len(words) == 0: return None
vague_clarity = calculate_vague_clarity_score(text, words) # 告知明确性
readability = calculate_readability_score(text, words)
fuzzy_total = round(0.5 * vague_clarity + 0.5 * readability, 2) # 严格按重构计算体系.pdf
rights_info = calculate_rights_score(text)
security_info = calculate_security_score(text)
acc_score = calculate_accessibility(text)
int_score = calculate_interactivity(text)
return {
"app_name": app_name,
"告知明确性得分": vague_clarity,
"可读性得分": readability,
"表述模糊性总分": fuzzy_total,
"accessibility_score": acc_score,
"interactivity_score": int_score,
"rights_score": rights_info["score"], "rights_missing": rights_info["missing"],
"security_score": security_info["score"], "security_missing": security_info["missing"],
"top5_high_vague": "; ".join([f"{w}({c}x80)" for w, c in Counter(words).most_common(5)]),
}
def compute_final_score(df):
def get_level(s):
if s >= 85: return "优秀"
elif s >= 75: return "良好"
elif s >= 60: return "一般"
elif s >= 45: return "较差"
return "极差"
df['final_level'] = df['表述模糊性总分'].apply(get_level)
df['rank'] = df['表述模糊性总分'].rank(ascending=False, method='min').astype(int)
df['合规性得分'] = round(df['rights_score'] * 0.5 + df['security_score'] * 0.5, 2)
result_columns = ['rank', 'app_name', '表述模糊性总分', 'final_level',
'告知明确性得分', '可读性得分',
'accessibility_score', 'interactivity_score',
'合规性得分', 'rights_score', 'security_score',
'rights_missing', 'security_missing', 'top5_high_vague']
df_final = df[result_columns].sort_values('表述模糊性总分', ascending=False)
df_final.to_csv(OUTPUT_FINAL, index=False, encoding='utf-8-sig')
print(f"✅ v17运行完成!结果保存至 {OUTPUT_FINAL}(表述模糊性总分已严格按50/50核心公式)")
return df_final
def main():
results = [process_per_policy(os.path.join(ROOT_FOLDER, f)) for f in os.listdir(ROOT_FOLDER) if f.lower().endswith('.txt')]
df = pd.DataFrame([r for r in results if r])
compute_final_score(df)
if __name__ == "__main__":
main()插件下载
想尝试插件效果的可以移步github下载
https://github.com/1MarsRain4/Privacy-policies-vague-accessibility-chrome-extention